
Background:
Academic research often involves exploring large bodies of literature to understand emerging concepts, identify patterns, and synthesize insights. Traditional keyword search falls short when trying to explore ideas by their meaning rather than exact terminology. This becomes especially problematic in fast-moving fields like AI systems design, where different papers may use varying terminology for similar concepts.
The Semantic Literature Explorer addresses this challenge by building a vector-database-backed research instrument that enables semantic exploration of academic literature. Rather than being a production tool, it serves as a practical learning project to understand how RAG systems actually behave when implemented.
The Problem
Conducting research into LLM system architectures presents several interconnected challenges:
- Keyword Search Limitations – Traditional search requires exact terminology matches, missing conceptually related content that uses different vocabulary.
- Scattered Knowledge – Key insights about orchestration, RAG patterns, and agent architectures are distributed across dozens of papers using inconsistent terminology.
- Theory-Practice Gap – Many academic papers discuss RAG and vector databases theoretically, but few researchers have hands-on experience building these systems.
- Evaluation Challenges – Without a working system, it's difficult to empirically test claims about semantic retrieval, chunking strategies, or orchestration patterns.
Core Research Question
The project centers on a fundamental question: How do modern AI system architectures like RAG, orchestration, and agent systems actually behave in practice when instantiated as real systems?
This question drives the entire architecture. Rather than building a polished product, the goal is to create a research instrument that provides empirical grounding for theoretical claims about LLM systems.
System Architecture
The architecture deliberately mirrors production LLM systems discussed in the literature, creating a seven-phase pipeline from PDF extraction to semantic synthesis:
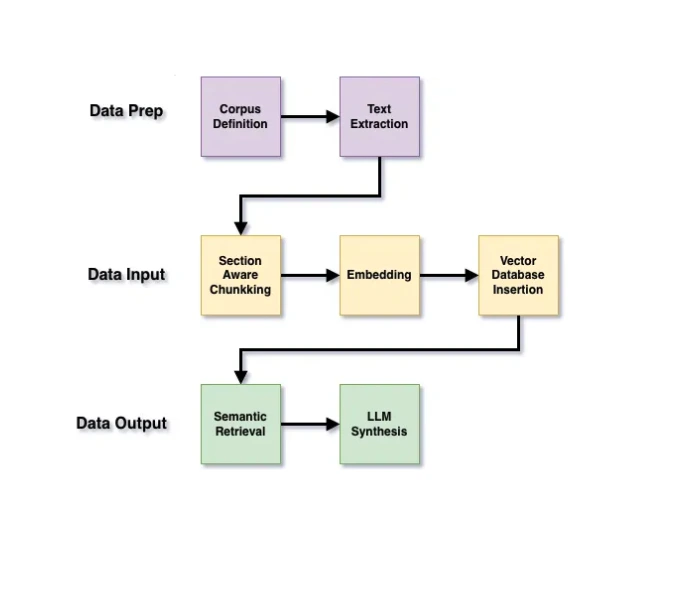
Phase 1: Corpus Definition
The foundation is a carefully curated dataset of 20-100 research papers focused on LLM architectures, RAG, multi-agent systems, orchestration, and governance. This controlled corpus enables systematic study while remaining manageable for a research project.
Papers are selected based on relevance to specific research questions, including both academic and industry sources. Each paper is clearly labeled with metadata including venue, publication year, and paper type, enabling temporal analysis and source filtering.
Phase 2: Text Extraction
Clean text extraction from academic PDFs requires careful handling of headers, footers, figures, and complex layouts. The extraction process preserves section structure and page-level organization, creating a foundation for semantic chunking.
Phase 3: Section-Aware Chunking
Unlike naive chunking that splits text arbitrarily, section-aware chunking respects the semantic structure of academic papers. Chunks are 200-300 words with approximately 20% overlap, with boundaries aligned to section headings where possible.
Each chunk carries rich metadata including paper title, authors, year, venue, section name, and paper type. This metadata enables filtering by source type, temporal analysis, and attribution in synthesized responses.
Phase 4: Embedding
Semantic search requires encoding text into high-dimensional vectors that capture meaning. The project uses sentence-transformer models to generate one embedding per chunk, creating semantic representations that enable similarity search by concept rather than keywords.
Phase 5: Vector Database
A local vector database stores embedding vectors alongside raw text and metadata payloads. This queryable semantic index enables fast similarity search while maintaining the flexibility to filter by metadata like publication year or paper type.
Phase 6: Semantic Retrieval
The retrieval system supports diverse query types tailored to academic research, including definition queries, comparison queries, trend analysis, and limitations or critiques. Queries are embedded using the same model, enabling top-k similarity search with optional metadata filtering.
Phase 7: LLM Synthesis
Retrieved chunks are passed to an LLM with strict grounding constraints: answers must use only the retrieved context with no external knowledge. This ensures responses are traceable to specific papers and prevents hallucination of claims not present in the corpus.
Research Questions
The system is designed to support investigation into seven core research areas, each with representative queries that test different aspects of semantic retrieval:
| Research Area | Example Query |
|---|---|
| Conceptual Definitions | How is "orchestration" defined across different papers? |
| Architectural Patterns | What patterns emerge for multi-agent coordination? |
| Vector DB & Retrieval | How do papers justify using semantic retrieval? |
| Orchestration & Control | What strategies manage control flow in LLM systems? |
| Evaluation & Failures | What failure modes are discussed for RAG systems? |
| Governance & Ethics | How are compliance requirements integrated? |
| Temporal Analysis | How has framing of agent systems evolved 2022-2024? |
Evaluation Strategy
Unlike production systems optimized for metrics, this project treats evaluation as a research method. The approach combines qualitative assessment with deliberate stress testing to understand system behavior.
Qualitative Evaluation
Manual review focuses on conceptual relevance: Are retrieved chunks actually addressing the semantic intent of the query? Does section-aware chunking produce more coherent results than arbitrary splitting? Where does semantic retrieval fail to capture meaning?
Architectural Stress Tests
The system is deliberately tested under challenging conditions to expose failure modes. This includes varying chunk sizes, changing top-k retrieval counts, introducing contradictory papers to the corpus, and asking intentionally ambiguous questions.
Crucially, failures are treated as research insights rather than bugs. Understanding where and why semantic retrieval breaks down provides empirical grounding for architectural decisions.
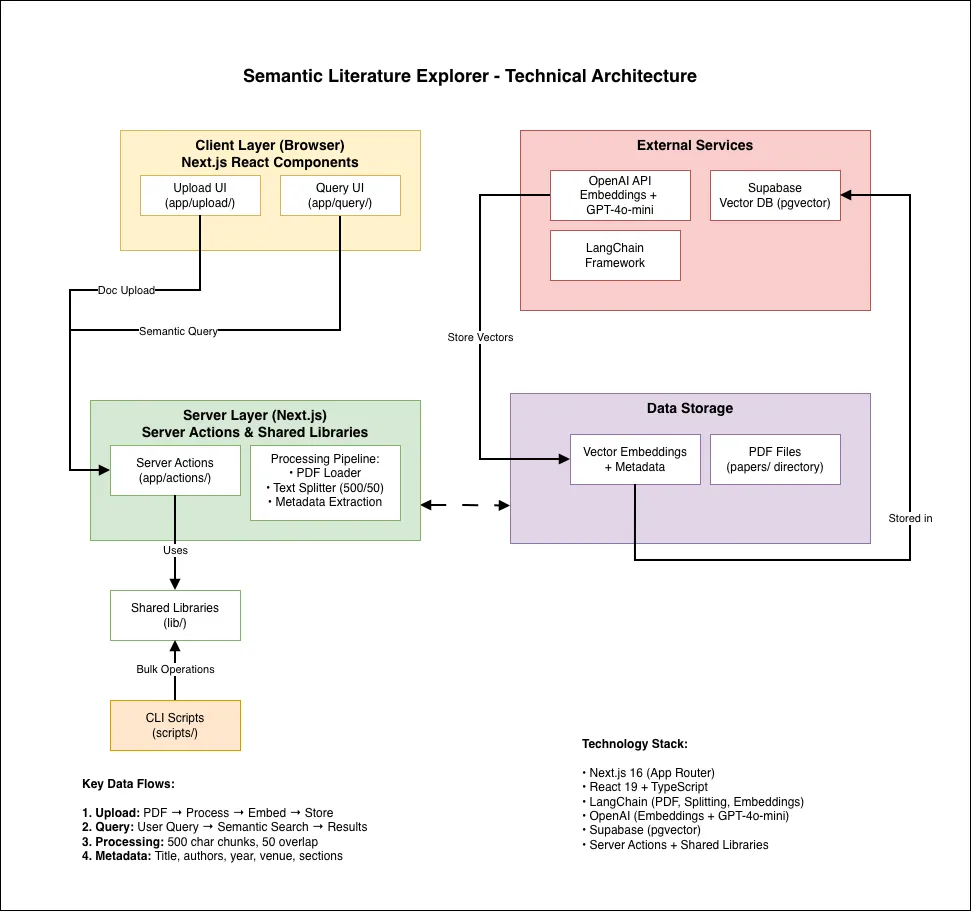
Technical Implementation
The project is built with Next.js and TypeScript, leveraging modern web technologies to create an interactive research interface. The technology choices prioritize learning and experimentation over production optimization.
Key technical decisions include selecting a local vector database for easy experimentation, choosing sentence-transformer models for embedding, and implementing metadata-rich chunking to enable flexible filtering and attribution.
Key Learnings
Building this system has already revealed important insights about RAG architectures, even before completion:
- Chunking Strategy Matters – Section-aware chunking that respects document structure produces more semantically coherent results than naive splitting.
- Metadata is Essential – Rich metadata enables filtering, attribution, and temporal analysis that pure semantic search cannot provide.
- Context vs Retrieval Trade-offs – There's a fundamental tension between retrieving enough context for the LLM to synthesize and keeping context windows manageable.
- Empirical Beats Theoretical – Actually building the system reveals failure modes and design constraints that aren't obvious from reading about RAG architectures.
Research Methodology Benefits
This project strengthens academic research by providing concrete artifacts to reference, enabling claims based on empirical observation rather than speculation, and grounding theoretical discussions in implementation reality.
By using a RAG system as a research instrument to study RAG systems, the project creates a unique feedback loop where the tool itself becomes a source of insights about its own architecture.
Conclusion
The Semantic Literature Explorer demonstrates how building practical systems can deepen understanding of AI architectures. By deliberately treating failures as insights and evaluation as a research method, the project goes beyond creating a functional tool to generate knowledge about semantic retrieval, chunking strategies, and RAG system design.
This approach of learning through building provides hands-on experience with vector databases, exposes real RAG failure modes, and creates empirical grounding for academic claims about LLM system architectures. The result is both a useful research instrument and a methodology for exploring complex AI systems through implementation.
The project is open source and available on GitHub, serving as both a research tool and an educational resource for others interested in RAG systems.